

Julia, the “Ju” in Jupyter, is a programming language that will soon be the standard in scientific computing, replacing MatLab and R, but is also popular on the server due to speed, multiple dispatch/type system, as well as a vast set of libraries that aid rapid application development.
- Julia Computing is not just the main team behind the language, but they’ve just as importantly built a robust development and deployment platform for developers, providing a cloud deployment layer to run large apps at scale in an optimized Julia environment.
- Solving the two-language problem at 10–100x the speed of Python using multiple dispatch with static type speed, yet really dynamically typed at its core.
In this article, we will explore two simple ideas with respect to Julia that led to our investment
- How the language is revolutionizing science, leading to world-changing scientific advancements, particularly in medicine, hard sciences and engineering.
- Next great modern language and platform upon which scientific and enterprise platforms (including databases such as Relational.ai) will be built.
Finally Evolving Scientific Computing
Scientific computing has been frozen in time since the 1950s with very little to no progression. The top languages of today are all relics of the past: Fortran (1957), Matlab (1960s), R (1976) are largely still similar to their original feature set and design. Although they’ve grown slightly over time to adopt more modern features such as Object-Oriented Programming, being dynamically typed and with the typical ML libs, these languages have not grown to be accessible for developers who grew up with Java, Python and C, let alone developers who expect parallelism, execution speed, native cloud computing support, just-in-time compilation (JIT), garbage collection, and more.
Two Language Problem
Julia was designed to solve this problem. It was born at MIT in 2012 by 4computer scientists from around the world: Viral Shah, Jeff Bezanson, Stefan Karpinski and the renowned Alan Edelman. Julia’s goal was to unify the world of more conventional languages such as C, Java, Python with the demands of the modern day scientific computing use cases to build “the best of both worlds”, while also applying lessons learned from the last few decades. This eliminates a huge problem in the scientific community—the so-called “two language problem”—a language can either be relatively easy for humans to write, or relatively easy for computers to run, but not both. Going back and forth between the two in the same program is extremely painful.
Features that make Julia a modern platform include ML functions as first class lib citizens, native GPU support, parametric polymorphism in a dynamic language, multiple dispatch, LLVM integration, dynamic typing (and really static if you choose), garbage collection and much more. Importantly, Julia is 10–100x faster than Python in almost all cases. All of this together (and much more), make Julia accelerate intense workloads for simulation and machine learning. The language has grown to ~1M worldwide developers, 38k GitHub stars and is taught at 1,500 universities including MIT, Stanford, Berkeley, CMU and more.
Due to the above, Julia has clearly become the choice of developers for scientific programming use cases and is quickly evolving to broaden itself beyond purely scientific orientations, to include users such as BlackRock, ASML and the Federal Reserve Bank. Julia has become extremely prominent in hard science/pharmaceutical companies such as AstraZeneca and United Therapeutics as well as dozens of other pharmaceutical companies around the world.
Fast-Rising Popularity
And if that weren’t enough, it was recently voted the fifth most loved language according to a recent Stackoverflow poll, above well admired languages such as Go and Node.js (can you even really call that a language?)
JuliaCon2021, the yearly worldwide developer conference recently held in July had 300 presentations from more than 20,000 conference attendees, which was an increase from 162 presentations and 10,000 attendees the year before, clearly we have massive adoption.
Community
Aside from packages contributed, the size of the community for the language is important, as it provides a safety net of sorts, knowing there is critical mass for continued investment and support over the years. For any dev team, this is certainly a concern before adopting something as core as a language.
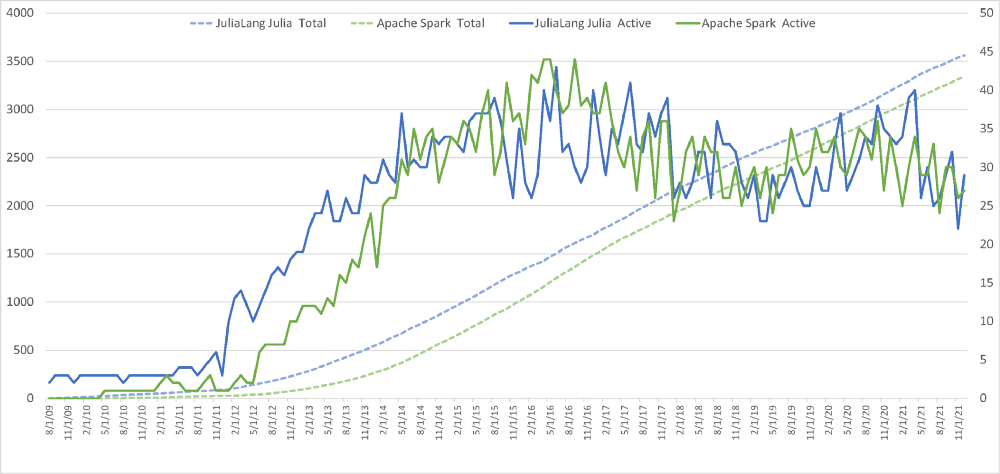
To look at this, we asked one of our data scientists to pull data comparing it to other large OSS projects, and we asked for a comparison against Spark, thinking it’d be much smaller, but provide some baseline.
Surprisingly, the data showed results that were shocking—the number of active JuliaLang contributors has tracked Spark contributions in the most parallel way possible. Yes, obviously Julia is a language and Spark is a platform, but they’re both really successful open source projects, and when you look at the data, the parallels in growth are incredible. For example, the graph below shows both active (contributing) developers month over month as well as total unique devs over time. Takeaway is they track identically, particularly for aggregate developers.
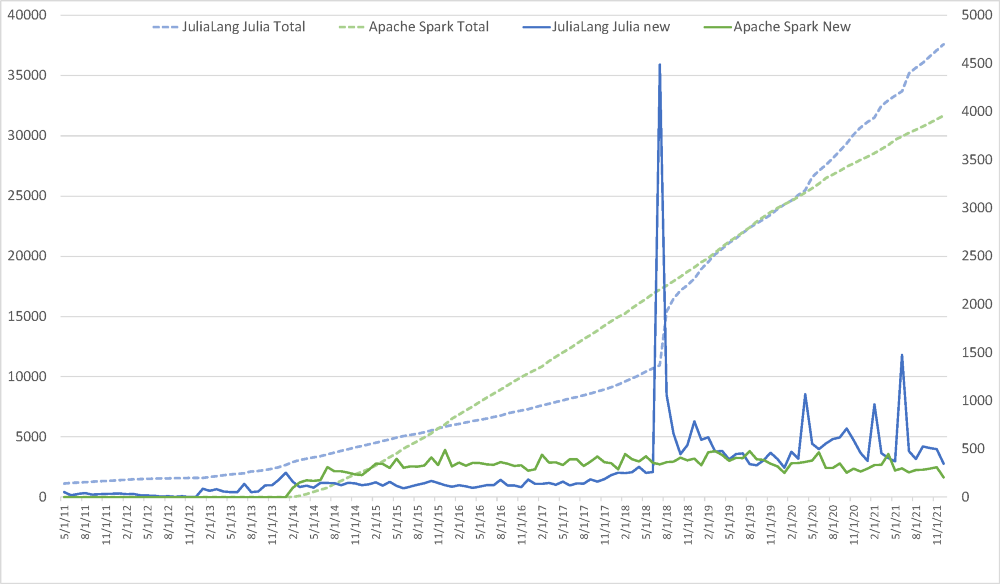
In the next graph below, new and total stargazers over time for Julia and Spark are shown. The spike around August 2018 is from the 1.0 release of Julia, as well as JuliaCon 2018 taking place at the same time.
Use Cases
So clearly the language and popular and growing, but why? Switching languages is rather painful for obvious reasons, but clearly devs are motivated by both what can be done with it and how it’s being done. The following sections will explore just that.
Pure Speed

Let’s talk about quantitative acceleration of CPU-bound tasks and also how that’s achieved. We know that Julia is fast for development, similar to Python and Matlab but with the speed of C that Python and Matlab don’t have. Let’s look at some benchmarks below that showcase just how fast, then get into why:
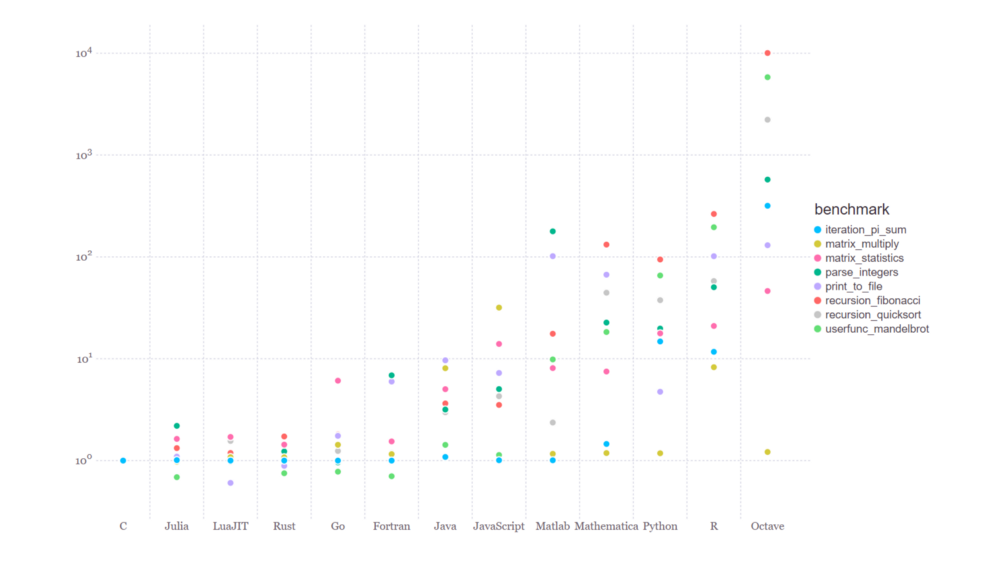
In the plot above, algorithms were implemented in an identical fashion across the languages on the x-axis for comparison purposes. Clearly, lower on the y-axis is better. You can find a detailed exploration of the data here.
So what’s making this fast? There are two major factors at play: the underlying JIT/LLVM implementation, and combination of the type system and multiple dispatch leveraging it. (At this point if you’ve been following along, Julia is just-in-time compiled to LLVM and then the underlying target architecture, likely x86 or ARM64 on Macs.)
Type System
Let’s first talk about the type system. Julia is somewhat funky in that it has a dynamic type system but with the speed advantages of static typing, where you can basically be sure of variable types. This in essence makes Julia fast, helping the JIT to generate efficient code from LLVM IR down to x86/ARM/etc, while preserving the flexibility you expect from traditional scripting languages like Python. In other words, you can both emit types and also provide explicit types through annotation, and when you do the latter, you’re really bringing multiple dispatch into the fold, while improving code readability and speed.
Multiple Dispatch
Now that we’ve gotten the type system out of the way, we can talk about how multiple dispatch makes Julia fast. Because the underlying JIT knows about the types in play at the point of function calls, the compiler can emit LLVM IR and x86 with all of the optimizations you’d get from using straight C! This is essentially why you can code in Julia but get C performance.
In plain english, Julia can dispatch (call) the correct methods/functions based on the type information it has on hand. For example, suppose you want to multiple two numbers. “Number” can be a lot of types obviously: 8-bit int, 32-bit int, 64-bit float. Ideally for optimization purposes discussed above, calling the fastest version that is optimized to leverage type information would be ideal—this is multiple dispatch. In other words, if you’re multiplying two 64-bit floats, call the method defined and optimized due do just that.
The example below (courtesy of Emmett Boudreau) is a fantastic example of the power of multiple dispatch. In the example below, predict() has been reduced down to a simple interface that can deal with any method to power the prediction:

For a great read on multiple dispatch, check out Stefan Karpinski’s “Unreasonable Effectiveness of Multiple Dispatch” talk from JuliaCon 2019.
As an illustration of how extensive and comprehensive multiple dispatch can be for simple operators like ‘+’, look no further than Julia’s own methods() function:

JIT
We keep talking about Julia compiling to LLVM IR to x86 (or other). This is really cool and one of the most interesting parts of Julia is seeing the intermediate representation of LLVM and the resulting x86, using a naive recursive fibonacci sequence function.

Using the @code_llvm macro in Julia dumps out the LLVM IR:

Then, a subsequent call to the @code_native macro prints the target arch assembly:

Rich Set of Libraries
Similar to Python, one of the most attractive aspects of Julia is the package library. The ecosystem contains more than 6,000 packages in the general registry. JuliaHub (discussed below) is one way to navigate and consume docs on the packages. One of my favorite aspects of the Julia REPL is the package manager, which you can start w/ the right square bracket character ‘]’. Here’s an example of listing installed packages:

JuliaHub
Cards on the table, Julia is an incredible language and the technologist in me fell in love. However, a language on its own is not really venture backable; there needs to be an underlying category defining, large economic opportunity when we invest, and fortunately that was the case with Julia Computing.
Julia Computing’s main product is JuliaHub, with an ever expanding list of domain-specific applications such as Pumas, in partnership with Pumas.ai, JuliaSim—a modern physical simulation system, and Cedar—a modern EDA tool. The language itself is open source and licensed under the MIT license.
JuliaHub is a combined cloud/SaaS browser-based integrated developer environment (IDE) as well as a cloud computing platform for deployment of Julia-based apps against hardware specifically configured to run Julia programs at scale.
Other features include package exploration/libraries and automatic config/deployment, build systems, debugging tools and more. The exploration piece is particularly interesting as developers can click a few buttons and pull packages directly into production.
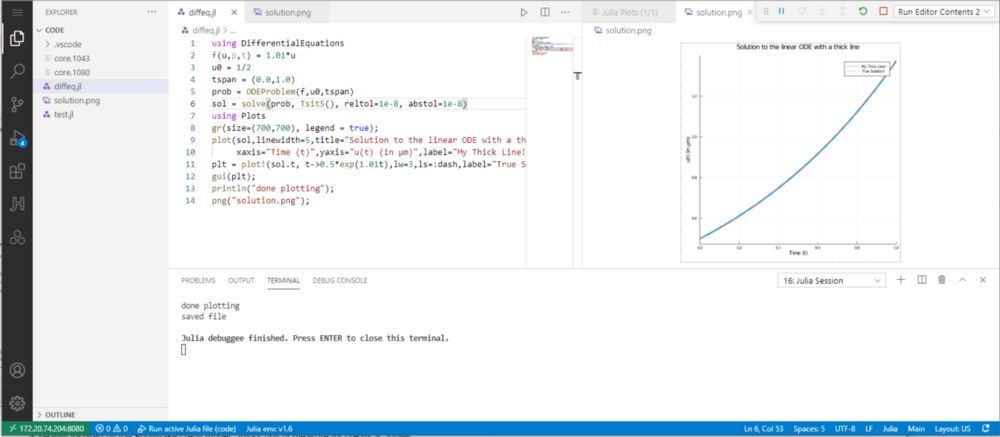
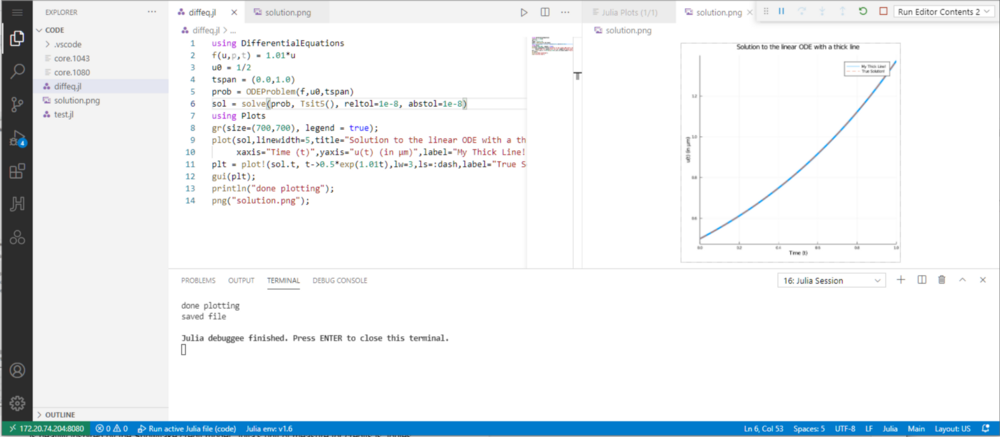
For example, we are going to show a trivial example of solving and plotting an ordinary differential equation (ODE), but before that we need an ODE package, which is available on JuliaHub. Installation is a breeze as is for every library a developer would need, as they are all stored in the cloud, similar to docker containers or python libraries:

A working session with a simple ODE solver and plot is shown below to illustrate a typical JuliaHub working session. The reason we are showing this is that we learned in customer references, that developers are doing things like solving differential equations or simple derivatives of quadratic equations offline by hand, then importing those functions back into the code, which is quite painful:
C Integration
One of the most thoughtful things about Julia is the so-called “no boilerplate” philosophy of avoiding all of the unnecessary hoops you typically have to jump through to call out to non-native libraries from a host language. Think JNI, for example, which is incredibly painful. Julia avoids all of this by making it trivial to call into arbitrary C library functions with no overhead. Here’s an example of calling into one of my favorite libc functions—htonl():
Python Integration
Another one of my favorite aspects of Julia is the Python integration, which is great for leveraging some of the existing well-understood Python libraries (ideally C-oriented) that can be called from Julia. Most notably, the Julia package PyCall does a great job for this, providing a few ways to integrate, coming very, very close to the no-boilerplate philosophy:
- inline integration where you can script Python using Python triple quotes
- “function pointers” into Python modules
Here’s a very naive example of both below where we simply grab access to NumPy’s pi value.
Julia Is a Language AND Platform
We mentioned the JuliaHub platform above, but have not touched on other apps that sit on top of Julia, which is really a platform as much as it is a language.
Pumas
One of the reasons Julia has seen such a huge uptick in the scientific community is thanks to the rich apps and packages integrated in the ecosystem. The one that is quite dominant and worth discussing here is Pumas, built by the Pumas-AI company, which according to the Julia site is a:
“…comprehensive platform for accelerating the availability of treatments to patients through health care data analytics. Scientists at pharmaceutical companies and regulatory agencies use Pumas to assess benefit-risk from valuable data.”
Pumas is a complete end-to-end modeling and simulation tool with a powerful productivity suite. Pumas is available on a fully compliant cloud environment as Pumas Enterprise. Pumas Enterprise is comprised of: Pumas (Toolkit suite, Productivity suite and Compliance Suite). The Toolkit Suite supports non-linear mixed effects modeling, physiologically based pharmacokinetic (PBPK), and quantitative systems pharmacology (QSP) models that are required by regulatory agencies such as US FDA and EMA. Pumas can also perform non-compartmental analysis (NCA), bioequivalence and in vitro-in vivo correlation (IVIVC) analysis providing a common toolset to perform all analyses in the horizontal of clinical drug development and clinical trial simulation. Pumas is the first platform to provide true integration of pharmacometric models with convolutional neural networks (CNNs) and other machine learning approaches. Pumas is massively scalable on any hosted or private cloud computing setups in conjunction with JuliaHub.
I recommend checking out some use cases from major pharmaceutical companies using Julia:
- Pfizer using Julia to accelerate therapy simulations for metabolic diseases by 175x
- AstraZeneca and Prioris.ai researchers using Julia, Flux.jl (ML)and Turing.jl to predict toxicity with a Bayesian neural network
According to the Pumas team, “Only 2% of pharmaceutical innovation successfully enters the market” while being based on pharmaceutical simulation and synthesis of new therapies is stuck in the 1960s and oriented around systems written in Fortran and Matlab. Pumas is disrupting that and bringing convolutional neural networks and other machine learning approaches to expedite simulation times in the lab. The ROI from modeling and simulation is multi-dimensional: reduction in analysis time, support product approval, skip/shorten trials, etc. In fact, it is used in 100% of regulatory filings of new products and used in the majority pharma strategy and dosing. Currently the Pumas product is being used by the likes of Moderna, P&G, Roche, Genentech, AMGEN, etc.
Pumas is built by experts who have experienced the pains in drug development first-hand and want to improve the efficiency and workflow of doing so. Instead of switching between various tools, Pumas is designed to be a one-stop shop that handles the entire analytical framework in one system.

For the data wrangling aspect, Pumas can support multiple formats and is also releasing support for images and unstructured data. Datasets from standard tooling like NONMEM are supported as well. Pumas also provides automated data summarization, interactive dashboards, and data handling.
After helping with the data ingestion and transformation process, Pumas provides out-of-the box algorithms for speed-ups in data analysis. For example, offering FOCE based analysis of discrete data models is only available in Pumas. In other tools, any discrete data models can only be done by Laplace approximation. In PK/PD modeling, being able to use FOCE provides huge time savings. And with Pumas, end-users do not have to set up or worry about parallelism.
Lastly, the team is increasing the auditability of the Pumas platform so that any project is traceable and reproducible. With its audit tracking feature, users can see every change made in the environment as well as the version history of the tools and packages used.
CSV and DataFrame Speed Crushing Python and R
For data scientists, DataFrames and Pandas are really the hammer and screwdriver for their jobs. And if you’re going to switch from Python to another language, there had better be a compelling reasons. Look no further than massive speedup when reading in DataFrames.
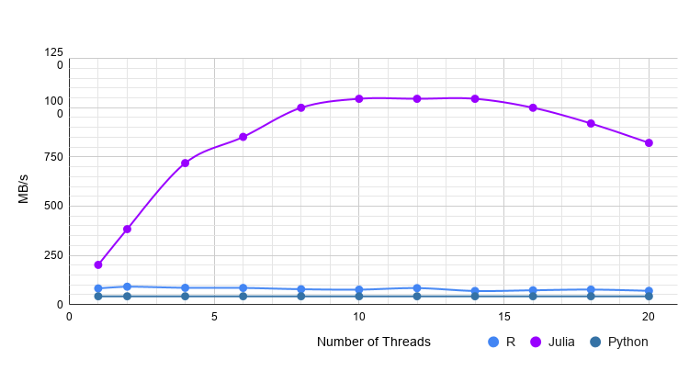
A very nice writeup was done in one of my favorite sites, towardsdatascience.com where Julia, Python and R were benchmarked against one another where csv file reads were compared for varying data types. As an example, the graph below shows ridiculous performance gains for reading strings in from a 1M row data set with 20 columns:
And a summary of performance across varying data types:

Aside from CSV performance, DataFrame processing speed has gotten remarkably fast for many operations, notably aggregation, though some work remains for joins. This chart below summarizes a GroupBy operation across a 5GB table, clearly showing it’s the fastest amongst popular operations (image taken from Stefan Karpinski’s talk during JuliaCon 2021 “State of Julia”)

Differentiable Programming (∂P)
One of the hottest subjects around the adoption of Julia, which we’d be remiss to not cover, is Differentiable Programming, or ∂P. ∂P is simply the ability to calculate gradients and automatically differentiate directly within the Julia language itself, moreover providing the capability to differentiate entire programs. A very simple example of differentiating a simple function is show below, the return value from the Zygote function gradient() would be 51.

What does this provide? One great example of using this for pseudo-real world simulation is in Matt Bauman’s fantastic talk about optimizing trebuchet calculations. He shows that given a multi-variable system where calculating trebuchet launch distance is based on wind speed, release angle and weight of the object being projected. Calculating derivatives with respect to each of the parameters individually would give you a gradient pointing in the direction of improving the system result (distance).

So if you have a function that can be differentiated across these variables to optimize distance, you can extend this system to make it faster and easier by building a neural network, that provides and optimizes the other dependent parameters (wind speed, target location) and have that NN output control parameters (weight, angle) to calculate error from target. Then you can use use that error and feed it back to the NN to calculate partial derivates to update the network and output new control signals. Classic machine learning but showing the power of ∂P to reduce complex systems to a few lines of Julia.

Of course no company is invested in with an inspiring set of founders with massive vision. The bios of the folks above speaks for itself—an incredibly remarkable set of world-renown developers, PhD’s and of course Dr. Edelman from MIT. This team is led by the incredibly thoughtful and visionary CEO Dr. Viral Shah.
Viral was actively involved in the Aadhaar project, which provided a 12-digit unique-identity number to Indian residents based on their biometric and demographic data. Based on his experiences implementing Aadhaar and other complex technology projects in the Government of India, he co-authored the book Rebooting India. With a set of folks such as Deepak, Stefan, Dr. Edelman, Jeff and Keno, Julia is set to be the language and platform of choice for the next four decades, much like Matlab, Python and R were.
Menlo Ventures is proud to support not just the Julia Computing team, but also the entire Julia ecosystem of developers and users worldwide. We can’t wait to see how Julia will change scientific computing and enterprise software for the next decade!

Tim is a partner at Menlo Ventures focused on early-stage investments that speak to his passion for AI/ML, the new data stack, and the next-generation cloud. His background as a technology builder, buyer, and seller informs his investments in companies like Neon (acquired by Databricks), Eve, Fleet, and Gimlet, among…




