VCs strive to be thesis investors, knowing that deep expertise and foresight are paramount to identifying and nurturing the most promising ventures. According to Investopedia, the definition of thesis-based investing is:
The term investment thesis refers to a reasoned argument for a particular investment strategy, backed up by research and analysis. Investment theses are commonly prepared by (and for) individual investors and businesses. These formal written documents may be prepared by analysts or other financial professionals for presentation to their clients.
This is precisely what Menlo did with Unstructured. Our knowledge was firsthand; our research and analysis were based on what we learned through our investments in AI/ML leaders like Pinecone, Anthropic, and Neon. As an engineer and developer myself, I had direct experience. I didn’t need to rely on the paid experts, PM and engineer references, and P&L analysis that often comfort investors. I understood the need for a product that connects to various data sources, prepares that data, and sends it to the appropriate destination—ideally built for AI-first product development. This insight led me to Unstructured—we knew the company needed to exist, but we hadn’t found it yet!
On the Lookout
We began looking for a solution to the problem and quickly settled on the obvious: Unstructured. Their product was already being utilized in production by companies and adopted by hackathons all around the world, and their customers were experiencing a great deal of success. We also heard the team was outstanding—which was quickly confirmed when we first met. We were excited by everything we learned and arrived at the following set of conclusions, which solidified our thesis:
- Unstructured has a killer product, driving tons of value
- It seems that every company on the planet building premiere applications for LLMs is using Unstructured
- Brian and the team are brilliant, highly motivated, driven folks who operate as an execution machine
- Rapidly growing customer base
In this post, we will cover 1–3 above.
Unstructured and RAG
RAG, or Retrieval Augmented Generation, is, for all intents and purposes, a household name in the tech world these days. If you haven’t come across it yet, it’s the de facto way of building applications that rely on LLMs to create content.
The issue is that, on their own, LLMs often lack sufficient data to generate cogent responses, or they hallucinate. That being said, LLMs are amazing content-creation machines—they’re great writers, but they need specific, relevant data to provide richer, more accurate creative responses. This is where RAG comes in. By feeding a smartly formatted dataset into the LLM prompt, beautiful responses can be output to the user. But where does that “smartly formatted dataset” come from?
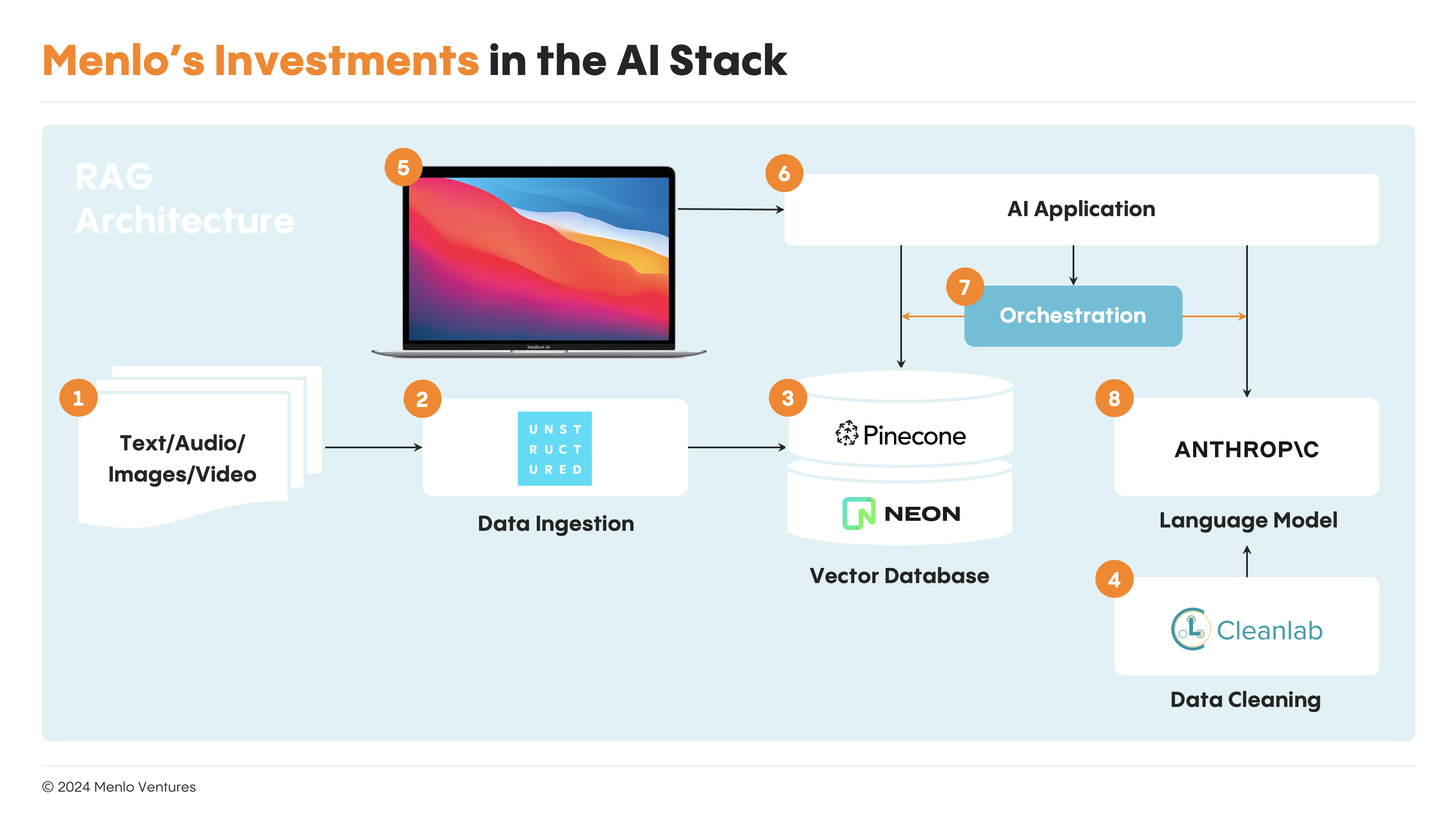
AI/LLM/RAG Pipeline Platform
The answer to the question above is that the data for the LLM prompt comes from a purpose-built vector database, such as Pinecone, or from an OLTP database with vector embedding support, such as Neon. These databases store vector embeddings (out of scope for this article) of unstructured data that represent either images, parts of video, or parts of text from data such as PDFs, emails, HTML pages, or other text. These “parts” of unstructured data are named “chunks.”
Now, where do those embeddings in the database come from? They come from what’s called an embedding model. Still, something has to execute a data pipeline, break up large unstructured data into chunks (unsurprisingly, this is called chunking, which can be fairly complex), feed the embedding model, and write the vector embeddings to the database.
This is what Unstructured does—it manages the end-to-end pipeline of sourcing the unstructured data from a source (local disk, Dropbox, Box, etc.), running an ETL pipeline (including chunking, calling embedding model), and writing the data to a destination (vector database or otherwise). In essence, Unstructured runs your data ETL for AI and ML.

Massively Popular Product
Based on the power of the ETL pipeline, the variety of connectors, and the ease of use of the platform and APIs, Unstructured has become the preferred way developers build AI applications and assemble data pipelines. The company is a cloud AI platform that helps developers build data pipelines for RAG, AI applications, chatbots, and more. The capabilities it provides within the ETL are connectors for all data sources (read and write), text chunking/extraction, integration with model providers to generate embedding, and more. The open-source project for Unstructured now has over 6,000,000 downloads, 5,200 GitHub stars, and nearly 100 contributors. The product can be used in several ways: command-line, programmatically via the API, and through the platform UI.
Team
I first met CEO Brian Raymond over email, but we met for dinner and a Sacramento Kings game. I immediately recognized Brian’s nose for great talent, great products, and passion for leadership. He has a compelling and diverse background; before founding Unstructured, he was VP of Public Sector at Primer.ai and an investment banker.
But then his background gets even more fascinating; he was on the National Security Council as Director for Iraq and, before that, an intelligence officer in the CIA. I love his diverse experience—it’s made him a thoughtful, creative, and dynamic leader, which you can feel after spending five minutes with him.

Conclusion
We’re excited to partner closely with Brian and the team at Unstructured and are confident that they have firmly established themselves as the ETL leader for AI/ML workloads of the future. Brian has done an incredible job on the product, assembled an all-star team, and pulled together a compelling set of current and future customers. Although the Kings lost to the Celtics on the night Brian and I first met, we feel like we won by getting to partner with Brian and the Unstructured team.

Tim is a partner at Menlo Ventures focused on early-stage investments that speak to his passion for AI/ML, the new data stack, and the next-generation cloud. His background as a technology builder, buyer, and seller informs his investments in companies like Neon (acquired by Databricks), Eve, Fleet, and Gimlet, among…

As a principal at Menlo Ventures, Derek focuses on early-stage investments across AI, cloud infrastructure, and digital health. He partners with companies from seed through inflection, including Anthropic, Eve, Neon, and Unstructured. Derek joined Menlo from Bain & Company, where he advised technology investors on opportunities ranging from machine learning…