
Generative AI apps have three core use cases with strong product-market fit today: search, synthesis, and generation. Menlo Ventures portfolio companies like Sana* (enterprise search), Eve* (legal research copilot), and Typeface* (AI for content generation) represent early breakout examples in each of these categories, centered on LLMs’ few-shot reasoning capabilities.
But the promise of generative AI extends far beyond this first wave of core use cases. AI that can read and write for you is great, but what’s even more exciting is AI that can think and act on your behalf. To this end, we’re already seeing leading app builders like Anterior, Sema4, and Cognition build solutions to take on workflows that previously could only be solved by armies of humans.
With new building blocks like multi-step logic, external memory, and access to third-party tools and APIs, the next wave of agents is expanding the frontier of AI capabilities to enable end-to-end process automation.
In our deep dive into the AI agents space, we’ll outline Menlo’s thesis for the emerging market—starting by defining what agents are and what made them possible. We’ll trace the architectural evolution of the modern AI stack from few-shot prompting through retrieval-augmented generation (RAG) to full-fledged agentic systems, before exploring the implications of this paradigm shift for the application and infrastructure layers in later articles.
What Are AI Agents? The Four Building Blocks for Cognitive Architectures
Fully autonomous agents are defined by four elements that, in combination, ladder up to full agentic capability: reasoning, external memory, execution, and planning.
- Reasoning. At the most basic level, agents must be able to reason over unstructured data. Foundation models like Anthropic* and OpenAI and are already incredibly effective at this out of the box, with a partial world model encoded into LLMs’ pre-trained weights that they leverage for general knowledge and basic logic.
- External memory. In addition to general knowledge, agents require external memory to store and recall domain-specific knowledge and the bounded context of the problem they are being tasked with solving, often via a vector database like Pinecone*.
- Execution. Agents use tools to perform tasks that enhance their problem-solving capabilities. Many early agent platforms provide toolboxes of custom actions pre-defined in code that their agents can choose from. But a number of generalized agent tools are also starting to emerge, including web browsing, code interpretation, authentication and authorization, and connectors with enterprise systems like the CRM and ERP to perform UI actions within those systems.
- Planning. Rather than attempting to solve complex problems via a single-threaded sequence of next-token predictions (like writing an essay all in one go, starting with the first word and not stopping until the last), agents follow a more human-like thought process of breaking down work into smaller sub-tasks and plans, reflecting on progress, and re-adjusting as needed.
Reference Architectures: AI Examples from RAG to Autonomous Agents
To be clear, the fully autonomous agents of tomorrow might possess all four building blocks, but today’s LLM apps and agents do not.
The popular RAG architecture, for instance, is not agentic but leverages reasoning and external memory as its foundation. Some designs like OpenAI’s Structured Outputs even enable tool use. The important distinction, though, is that these applications leverage the LLM as a “tool” for semantic search, synthesis, or generation, but the steps they take (i.e., their logic flows) are still pre-determined with code.
By contrast, agents emerge when you place the LLM in the control flow of your application and let it dynamically decide which actions to take, which tools to use, and how to interpret and respond to inputs. As long as this is true, some agents don’t even need to interact with external tools or take actions.

At Menlo, we’ve identified three types of agents that vary in their primary use cases and degrees of freedom in controlling the flow of application processes.
At the most constrained end are “decisioning agent” designs, which use language models to traverse predefined decision trees. “Agents on rails” provide one degree more of freedom by equipping agents with a higher-level objective but constraining the solution space with a SOP to follow and a predetermined library of “tools” to choose from. Finally, at the far end of the spectrum lie “general AI agents”—essentially for-loops with little to no data scaffolding on top, that rely entirely on the language model’s reasoning abilities for all planning, reflection, and course correction.
Below, we examine five reference architectures and AI agent examples for each of these agent types.
Retrieval-Augmented Generation (RAG)
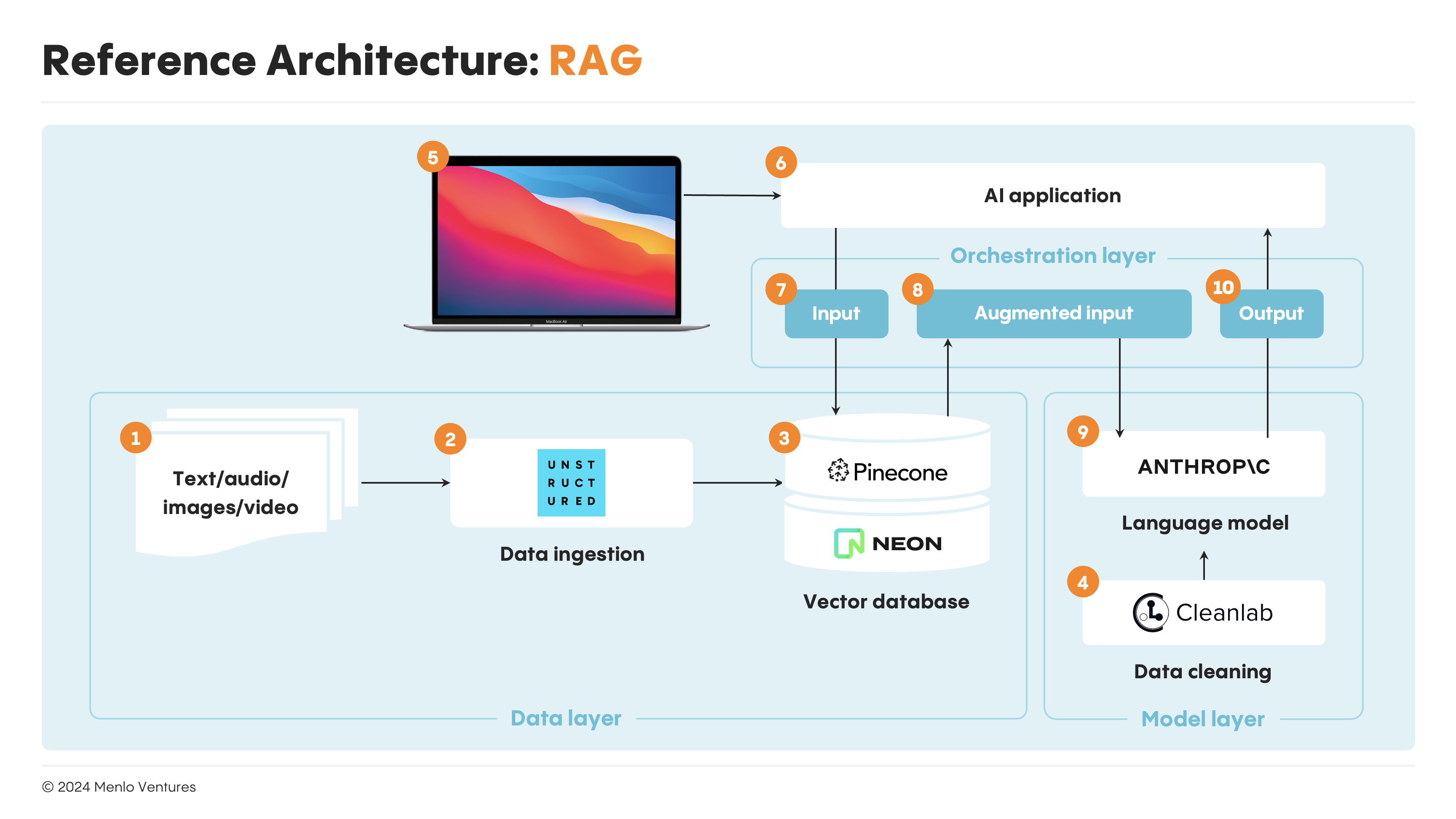
To set the baseline: RAG is the standard architecture for most modern AI applications today. Let’s take Sana’s enterprise search use case as an example of how it works under the hood.
The process begins with the application loading and transforming unstructured files (e.g., PDFs, slides, text files) across enterprise data silos like Google Drive and Notion into LLM-queryable formats, often through a data pre-processing engine like Unstructured*. These files, now “chunked” into smaller blocks of text that allow more precise retrieval, are embedded as vectors and stored in a database like Pinecone*.
When a user asks a question of the AI app (e.g., “Summarize all my notes from meetings with Company X”), the system retrieves the most semantically relevant context chunks and folds them into a “metaprompt” augmented with the retrieved information to feed the LLM. The LLM then synthesizes an answer from the retrieved context to return to the user a neat, bulleted answer.
Of course, the diagram only illustrates a single retrieval step with one LLM call. In production, AI apps have much more sophisticated application flows with tens if not hundreds of retrieval steps. These apps often feature “prompt chains” where the input of one retrieval step feeds into the next, and multiple “prompt chains” execute in parallel for different types of tasks. The results are then synthesized together to generate the final output.
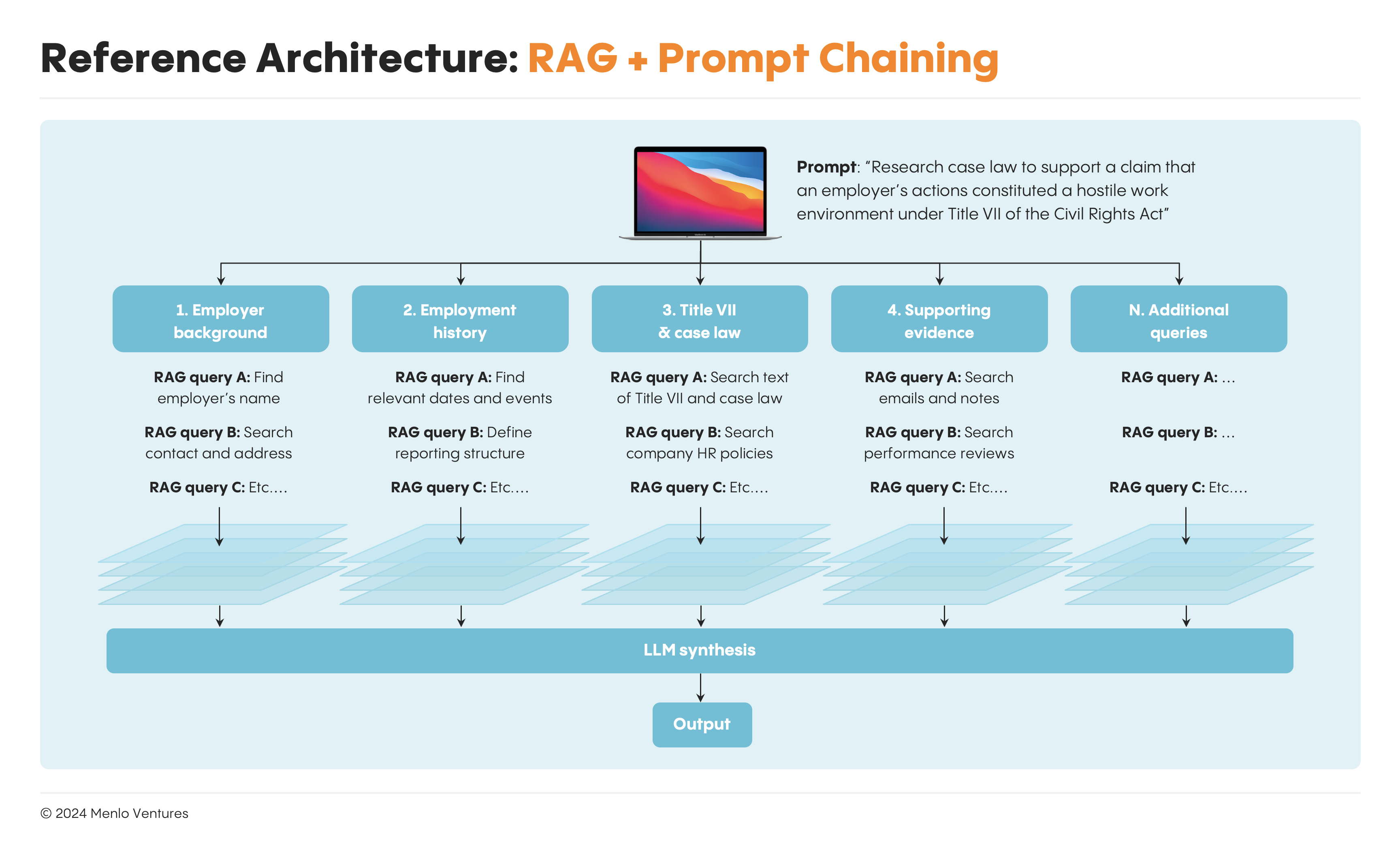
The legal research copilot Eve*, for instance, might break down a research query on Title VII into separate prompt chains focused on predetermined sub-topics like employer background, employment history, Title VII, relevant case law, and supporting evidence for the plaintiff’s case. LLMs then run each prompt chain, generate an intermediate output for each, and synthesize across the outputs to write a final memo.
Tool Use
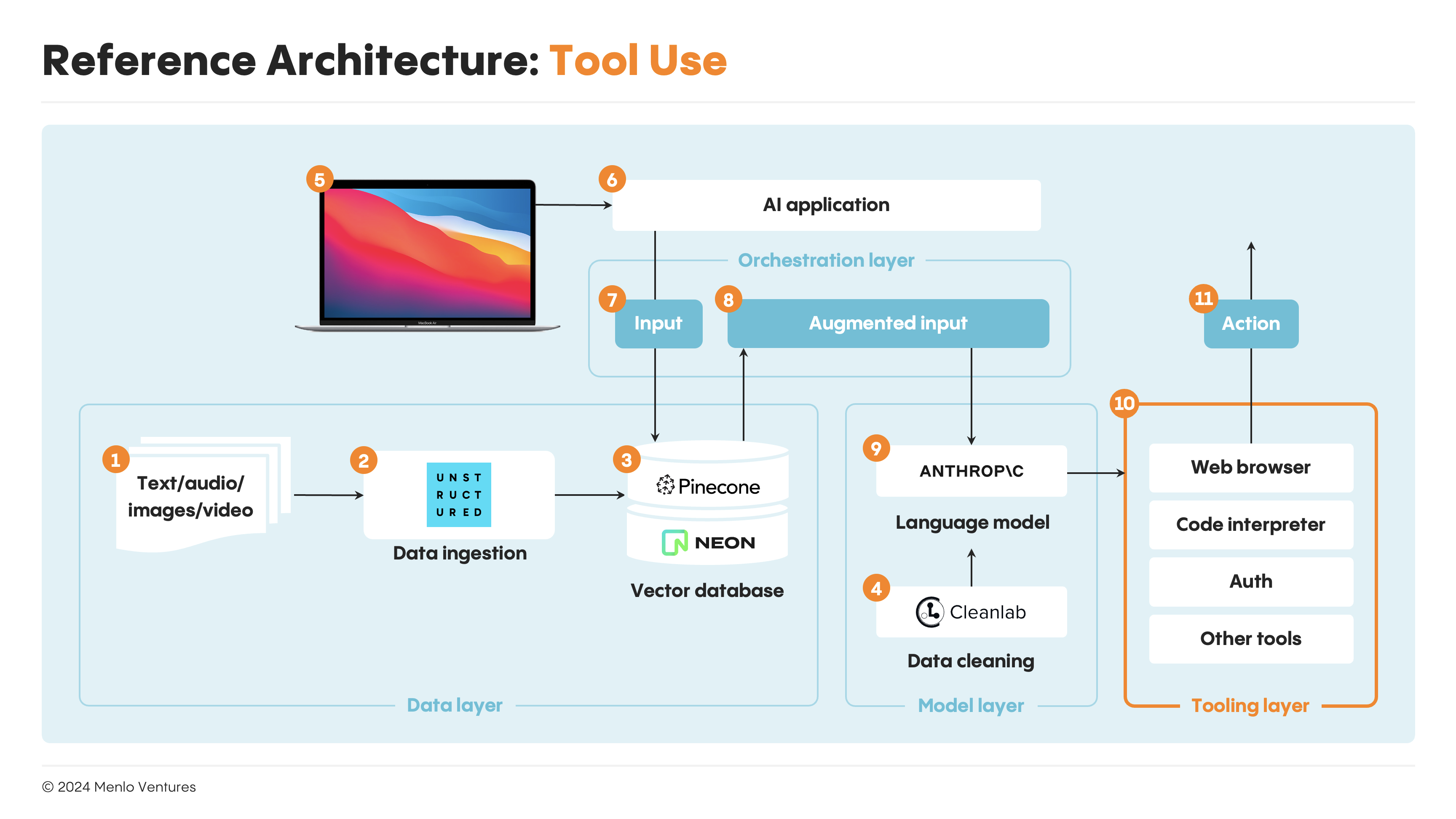
Tool use, or function calling, is often seen as the first half-step from RAG to agentic behavior, adding a new layer to the modern AI stack.
These tools, essentially pre-written code components, execute specific actions. Popular primitives like web browsing (Browserbase, Tiny Fish), code interpretation (E2B), and authorization + authentication (Anon) have already emerged. They empower LLMs to navigate the web, interact with external software (e.g., CRMs, ERPs), and run custom code. The system presents available tools to the LLM, which then selects one, crafts the necessary inputs as structured JSON, and triggers API executions to produce the end action.
Omni’s Calculations AI feature exemplifies this approach. It leverages a LLM to output appropriate Excel functions directly into the spreadsheet, which then performs the calculation and automates the generation of complex queries for users.
This being said, tool use is powerful but, by itself, cannot be considered “agentic.” The logical control flows remain pre-defined by the application. True agents, which we’ll explore in upcoming designs, allows LLMs to dynamically write part or all of their own logic.
Decisioning Agent
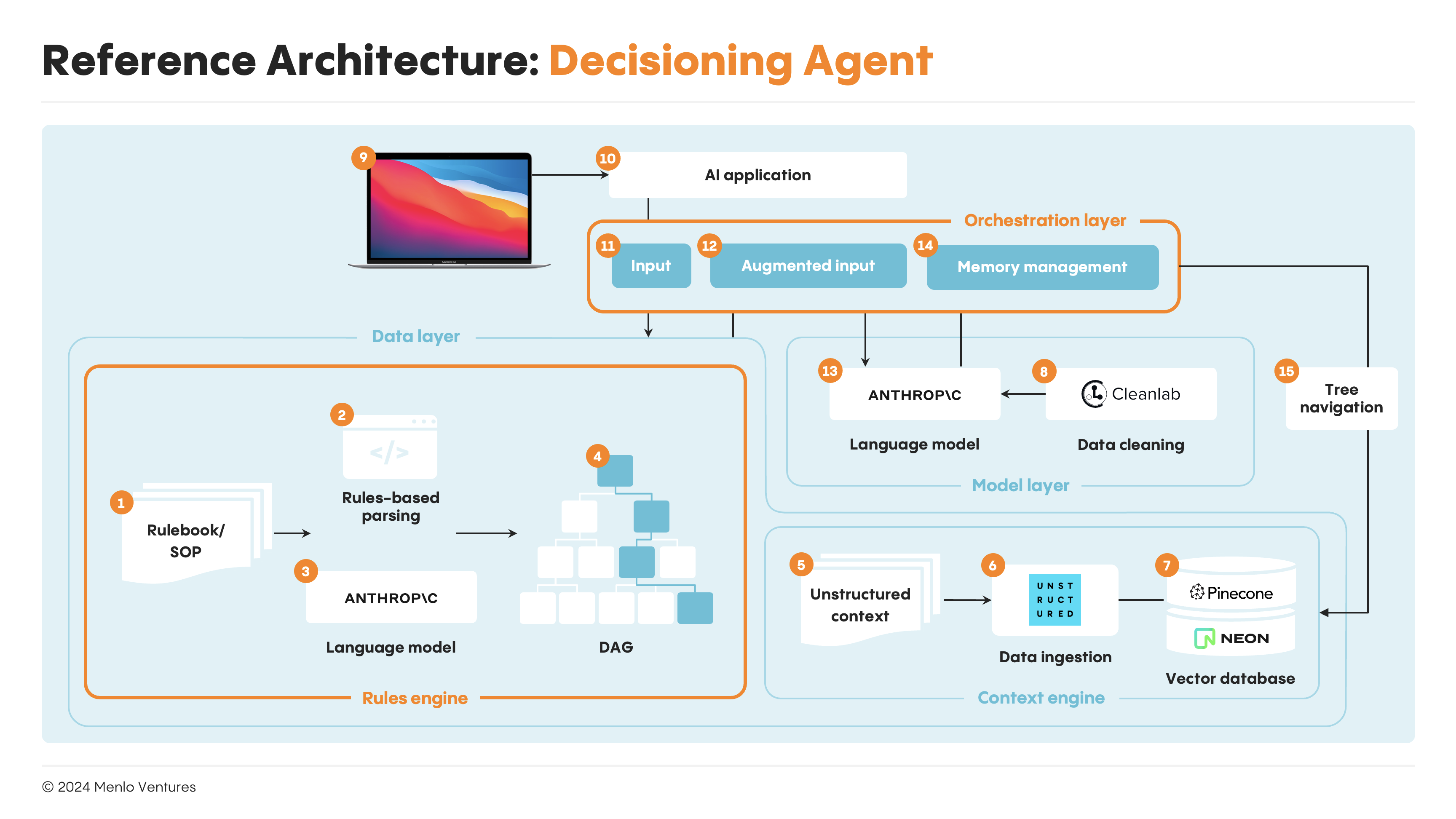
The first type of agents we’ll explore is decisioning agents, which use agentic decisionmaking to navigate complex, multi-step reasoning flows and arrive at business decisions. Unlike RAG or tool-use approaches, this architecture cedes some control logic to LLMs for the first time, instead of having all steps hard-coded in advance—but still sit at the lower end of the range for agentic degrees of freedom, as the agent acts primarily as a router navigating a set decision tree.
Let’s look at Anterior (fka Co:Helm) as an example. The health plan automation company has developed a clinical decisioning engine to automate claims submission reviews. Nurses today complete these reviews by hand, based on binders of payer rules laden with conditional knowledge (like the world’s most boring “choose your own adventure”).
Anterior streamlines this process. The company first transformers payer rules into a directed acyclic graph (DAG) using rules-based scripts and language models. Their agent then traverses this decision tree, leveraging LLMs at each node to evaluate relevant clinical documentation against specific rules. For simpler nodes, this might involve a basic retrieval-augmented generation (RAG) step. However, Anterior often encounters more complex tasks requiring a subchain, where the agent must select the optimal approach before advancing to the next node. It updates its state with each decision (managing this intermediary output in-memory), progressing through the tree until reaching a final determination.
Anterior is not alone in this approach. Others leveraging decisioning agents in other domains include Norm AI, which is building AI agents for regulatory compliance, and Parcha, which is building agents for KYC.
Agent on Rails

The next class of agents we’ll look at are agents on rails. In contrast to decisioning agents, agents on rails are given higher-order goals to achieve (e.g., “reconcile this invoice with the general ledger,” “help the customer troubleshoot a login issue,” “refactor this code”) and empowered with more degrees of freedom to choose the approaches and tools to achieve those goals.
At the same time, these agents are still guided by procedural knowledge about how the organization expects the agents to perform (the “rails,” represented as a rulebook or instruction manual written in natural language); given predefined tools enabling set actions in external software systems; and bound by guardrails and other review measures to prevent hallucination.
At runtime, this design might result in the following pattern:
- The planning agent assesses the current state of the application relative to the runbook (i.e., which node in the DAG it is currently sitting at) and inspects all the action chains available from that node;
- The agent selects and executes the best chain. Each chain might include pre-written actions defined as code, or even additional agents that can perform specific tasks includes traditional RAG;
- Before any action is taken, the system applies a review and guardrails for consistency and alignment;
- The planning agent assesses the new state relative to the rulebook and the process is repeated—picking the best chain to execute again from the new node in the DAG.
Note that this architecture introduces another order of complexity to previous designs, which might be supported by additional data infrastructure including that for durable execution; state and memory management for episodic, working, and long-term memory; multi-agent orchestration; and guardrails.
Leading agent companies appear to be converging on this architecture as a happy medium between autonomy and control. Emerging AI agent examples include Sierra, Decagon, Maven AGI, DevRev, and Gradient Labs in customer service + support; Factory AI and All Hands AI* in software development; Sema4 in the financial back office; and many others across spaces like the sales, security operations, and supply chain.
General AI Agent
The final, still unattainable holy grail of agentic designs is the general AI agent—a for-loop architecture where the LLM’s advanced capabilities subsume the structured “rails” of previous designs. This hypothetical agent would possess dynamic reasoning, planning, and custom code generation abilities, enabling it to perform any action in external systems, not just predefined ones.
Research progress toward this ideal has surged since BabyAGI and AutoGPT emerged in spring 2023. Currently, the most sophisticated design is Language Agent Tree Search (LATS), which adapts Monte Carlo Tree Search—the model-based reinforcement learning technique behind AlphaGo—to language agents. LATS allows agents to explore multiple trajectories for achieving an objective function, prioritize high-reward paths, incorporate feedback, and backtrack when necessary.
Pioneering commercial applications of these frontier architectures include new foundation models like Reflection AI, as well as coding agents like Cognition, Nustom, and OpenDevin/All Hands AI.
What’s Next
Generative AI is entering its agents era. The agentic architectures and early examples we see today represent only the beginning of a broader transformation that promises to redefine the human-machine dynamic, with implications for both enterprise applications and infrastructure. In upcoming articles, we’ll explore these topics further.
Meanwhile, if you’re building in the agents space, we’d love to connect.
Tim Tully ([email protected])
Joff Redfern ([email protected])
Deedy Das ([email protected])
Derek Xiao ([email protected])
*Backed by Menlo Ventures

Tim is a partner at Menlo Ventures focused on early-stage investments that speak to his passion for AI/ML, the new data stack, and the next-generation cloud. His background as a technology builder, buyer, and seller informs his investments in companies like Neon (acquired by Databricks), Eve, Fleet, and Gimlet, among…

A self described “tall, slightly nerdy product guy,” Joff was previously the Chief Product Officer of Atlassian, responsible for leading its acclaimed portfolio of products, including Jira, Confluence, and Trello. During that time, Joff was named on the “Global CPO 20” list by Products That Count and as a “Top…

Deedy is a partner at Menlo Ventures focused on early-stage investments in AI/ML, next-generation infrastructure, and enterprise software. Having been an engineer and product leader at both a successful startup and large public companies, Deedy is well-equipped to help technical founders navigate how to build and scale enduring tech companies.…

As a principal at Menlo Ventures, Derek focuses on early-stage investments across AI, cloud infrastructure, and digital health. He partners with companies from seed through inflection, including Anthropic, Eve, Neon, and Unstructured. Derek joined Menlo from Bain & Company, where he advised technology investors on opportunities ranging from machine learning…



