

TL;DR
Edge Delta is providing a whole new class of product and category—a complementary and incredibly necessary approach to observability—edge observability, a critical component of your new data stack.
Four things you need to take away:
- Hybrid data architectures are the new standard and edge observability is the missing piece. Smart architectures are increasingly pushing down the processing problem to the edge, in some ways a predicate pushdown for the entire data stack! This mode of processing the data facilitates the following three takeaways:
- Preprocessing at the point of data collection reduces egress costs out of your data center and/or cloud service provider as it goes to major log analytics and observability systems. Additionally, you can reduce the size of the data by processing at the edge, in the agent through a centrally managed agent fleet manager.
- Not just a pricing arbitrage, but a complete edge observability solution. This is way bigger than just a new product—it’s a new category.
- Amazing set of founders between Ozan and Fatih, with a team that shared my vision of what’s next in the new data stack.
Edge Delta changes everything you thought about data, moving you from a world of manual and complicated agent configuration, high latency alerting, hitting the limits of the physics and costs of large datasets at the petabyte level—to a world powered by the collective obsession of the some of the best engineers on the planet; with a singular focus to help you concentrate on the data you care about, with alerts you need. Edge Delta was designed from the ground up to be more elegant and more efficient than anything else before.
The Longer Explanation
They created a vision for our data future with an edge observability platform with a streaming agent powered by decentralized machine learning that scales to any volume and size of data, giving you alerting and metrics on top of reduced data volume.
In my past life as CTO of Splunk, I had envisioned a world of pushing down processing to the edge as much as possible. This would create a bifurcated processing model where the heavy lift data crunching at the edge would materialize views of the data and prepare it for arrival in the cloud applications. Doing this as mentioned above has advantages of cutting down the volume of the data, but also reducing latency. Over time Edge Delta will extend this beyond metrics and log aggregation and extend it to application-level use cases such as security threat detection, ITOps, Observability and BI use cases.
Before Edge Delta, the traditional centralized platforms had limitations which forced teams into making concrete decisions that forced engineering teams into rigid data pipelines. Edge Delta is taking a modern approach to observability by giving enterprises the ability to use distributed stream processing and federated machine learning capabilities for intelligent, dynamic, and automated data routing to optimal destinations. Rather than neglecting datasets to solve for technical and financial constraints, organizations now have access to limitless analytics and unparalleled visibility leading to significant operational efficiencies previously not possible.
When I first started to configure Edge Delta in my local network, I found it incredibly simple to install; I installed the agents and was blown away by the slick UI. The next thing that stood out was the efficiency and capability of the agents and daemonsets: incredible performance and imperceptible footprints that were unintrusive and imperceptible in terms of effects on resources. Time to value was less than five minutes.
The Problem Being Solved
The world already knows that logs are important, large players such as Splunk, DataDog, Sumo Logic and more make timeseries search and query of logs instantly scalable. However, all of that comes at a very, very high price, which seems somewhat reasonable given the storage and compute requirements to power complex queries across broad time dimensions and large-scale joins. They have to pass on the cost of the underlying cloud infrastructure to the user.
Since data is only continuing to grow, those costs aren’t going to come down anytime soon; very simply the more data you have, the more hardware necessary to scale out. But what if there was a new type of product that could act as a reverse proxy for SaaS log analytics providers and preprocess data before it was sent to the cloud for ingestion? A solution like this would not only reduce costs but provide an entire new approach to data analytics—at the edge.
Edge Observability
What if the data could be reduced in volume, aggregated, enriched and filtered at the edge, before even leaving the host? But what about taking that one step further than being just a pricing arbitrage and doing anomaly and error detection at the edge, as well as using distributed machine learning (both scoring and training)?
All of those rhetorical questions were answered by Edge Delta. When I first read their pitch deck I spit out my coffee as they had already figured out an idea I’d been previously chasing. Edge Delta’s breakthrough processing paradigm is reinventing the architecture of the new data stack altogether, creating a category that hadn’t existed before—Edge Observability.
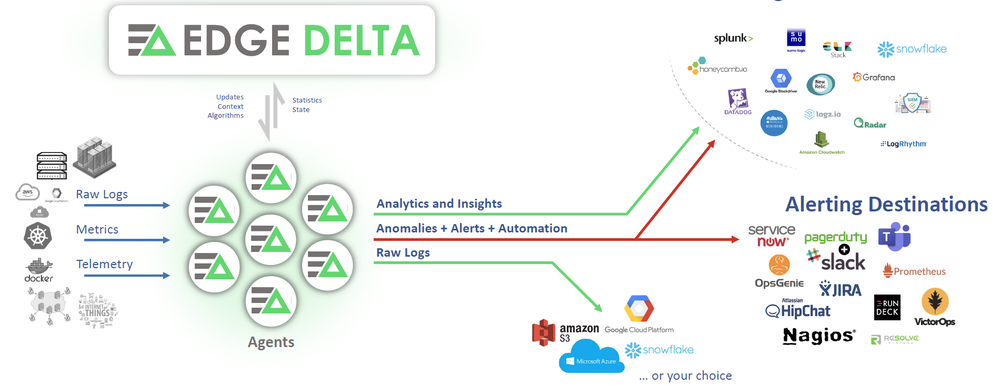
Edge Delta is a novel approach to data processing—as it’s pushing down the compute to the edge, solving five critical problems:
- Lower latency alerting and error detection powered by edge-based machine learning using smart agents that do far more than store-and-forward logs.
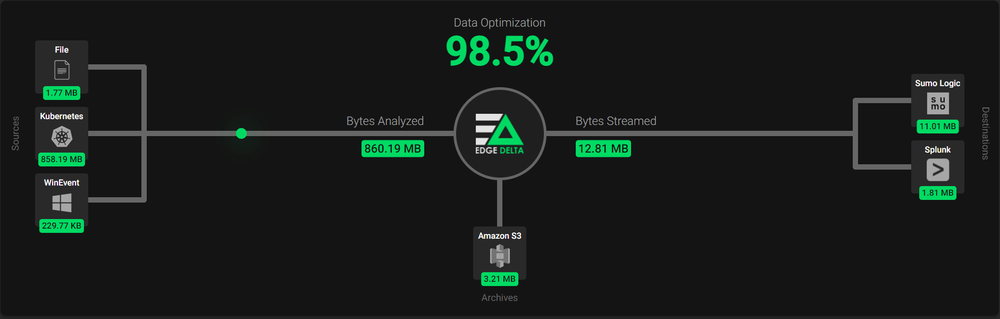
- 93–98% reduction in log volume sent to ingest-based log pipelines.
- Reduced egress costs from the data center or between public clouds.
- Fleet management of the data collection agents through a centralized agent config UI in the cloud.
- Automatic setup of an observability solution behind the scenes for you—immediately enabling full text search across your logs and metrics.
By reducing the volume of ingest and making data more manageable and affordable at the same time, customers are getting more valuable out of their data solutions. Along the way I met one customer that had to disable logging altogether because they hit affordability limits of their ingest license. Moving to this model allowed them to reenable logs!
Show Me the Data
How do I know this reduction is real? Because I deployed a fleet of Edge Delta agents to various types of endpoints/hosts in my house to validate the solution! I deployed the agents on Windows laptops, Ubuntu inside Hyper-V, Kubernetes daemonsets, Linux bare metal, Macs and more. This data was reduced significantly at the edge, with anomalies sent to the Edge Delta cloud reporting UI, but the raw logs sent to Splunk, Sumo Logic and S3.
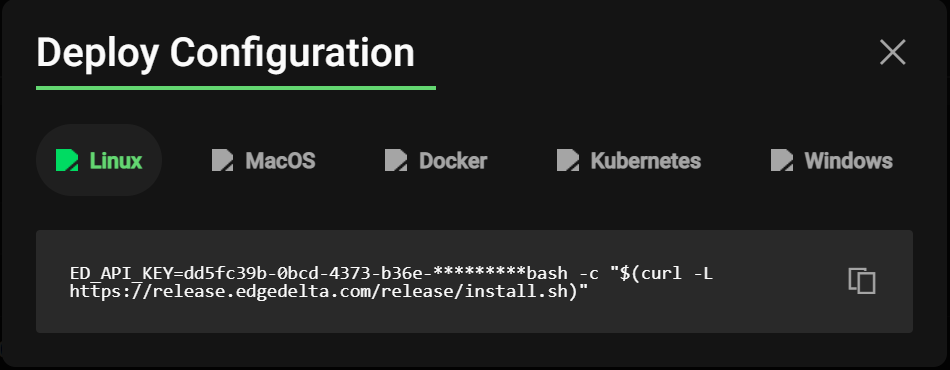
Installation
Installation to test was insanely easy. For example, installation on a linux box is a single line of setting an environment variable and running a bash script:
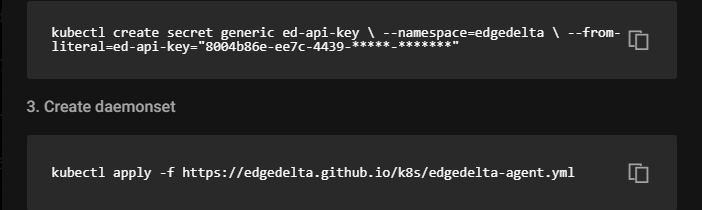
Or in the case of Kubernetes, “kubectl apply” to create the daemonset:
Configurating Data Destinations and Integrations
Adding data destinations for a massive routing system like Edge Delta had better be easy, fortunately that was figured out. All popular destinations are already ready for configuration, with the menu growing all the time:

What’s nice is adding any one of these is a breeze—no hand-configuring of XML, YAML or TOML, it’s all in the UI:
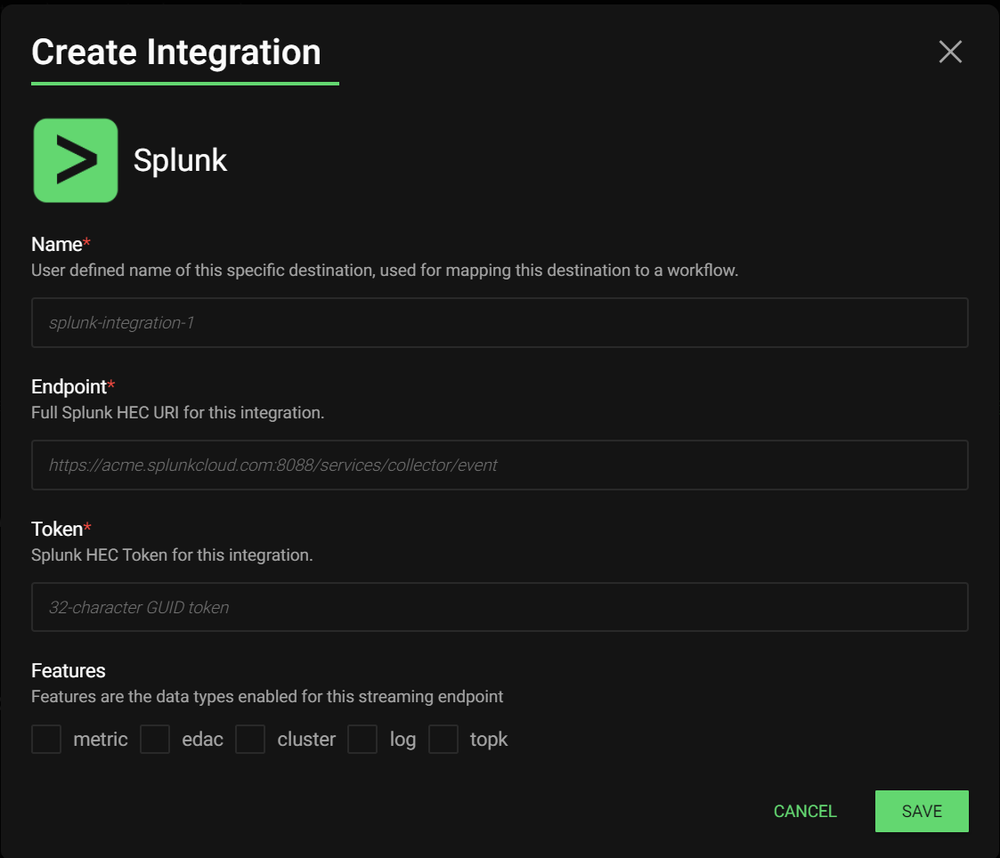
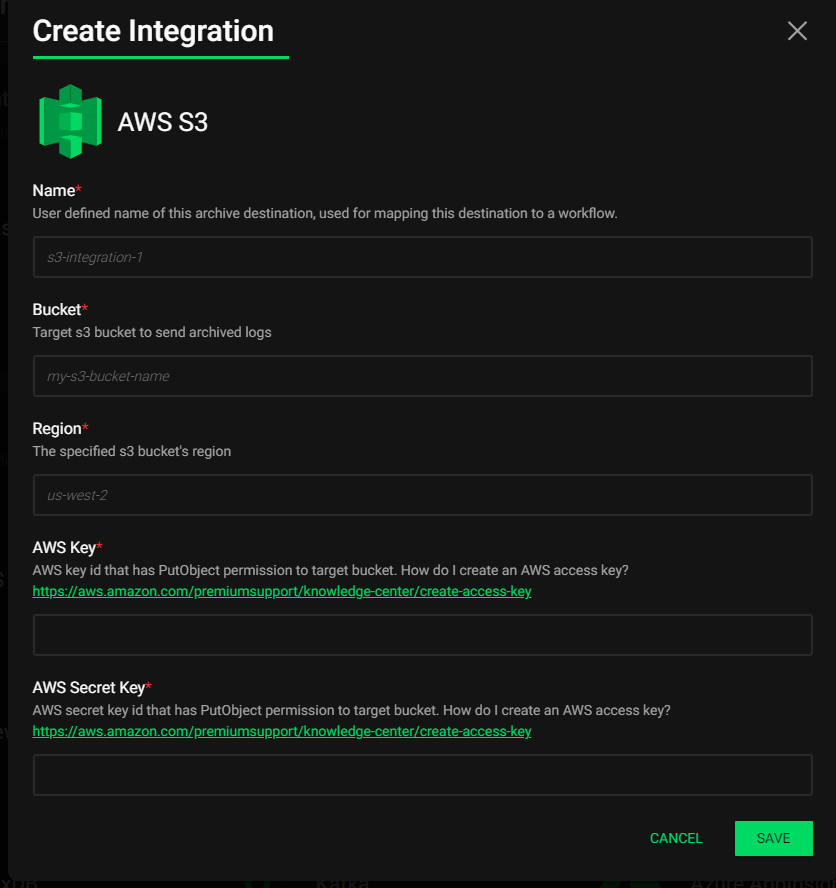
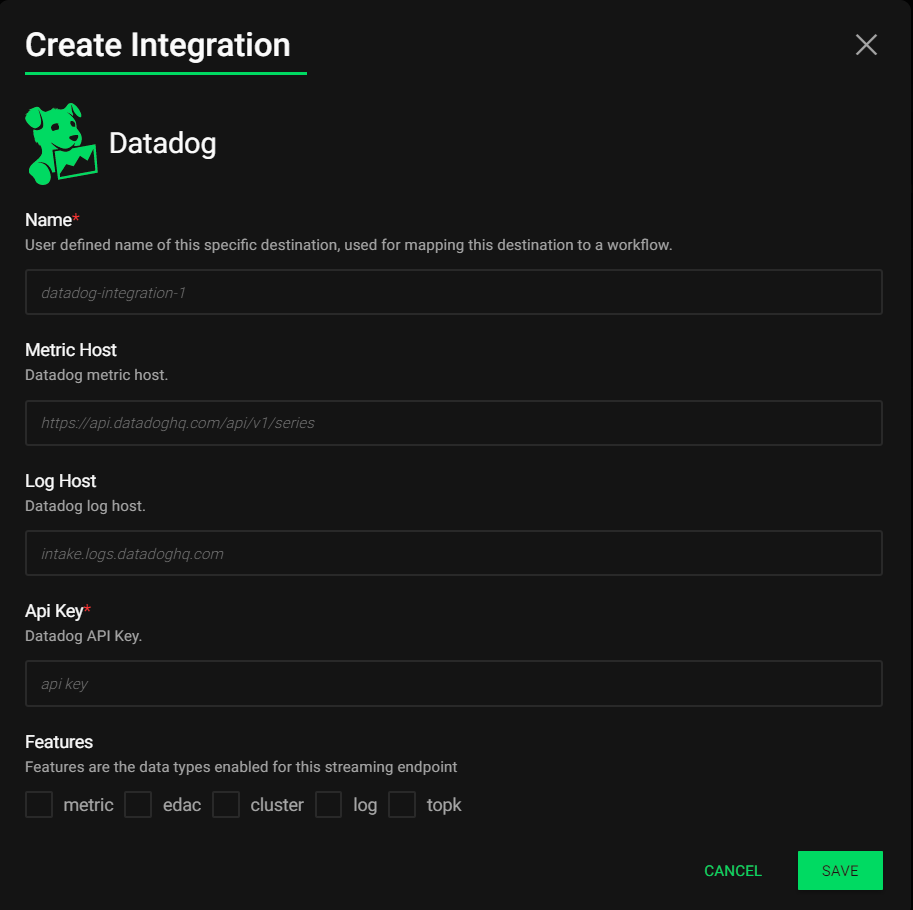
Fleet Management
One of the other really key ideas while pushing OpenTelemetry at Splunk was the idea of fleet management—or the ability to centrally configure thousands or tens of thousands of agents running on endpoints from a cloud UI. Fortunately, Edge Delta had this solved as well. The UI allows you to manage and version control agent configurations. In addition to the UI-based configuration of the agents, for the more editor-inclined power users, config can also be done in YAML:
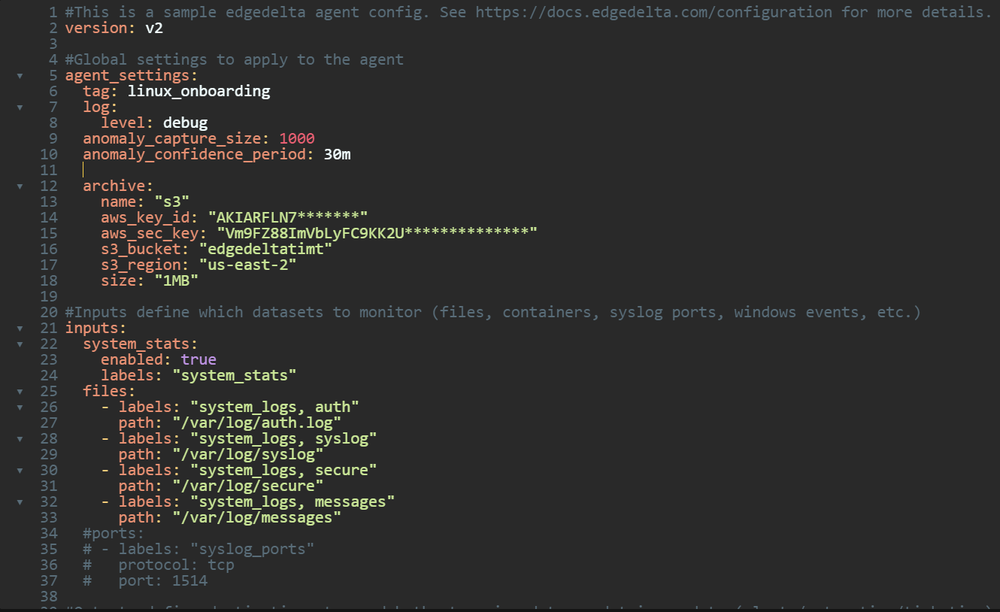
Whenever a change is made in the UI—it’s automatically pulled down to the correct agents as the agents poll for new configs every minute (or some configurable long polling timeout.)
Logs, Insights and Metrics
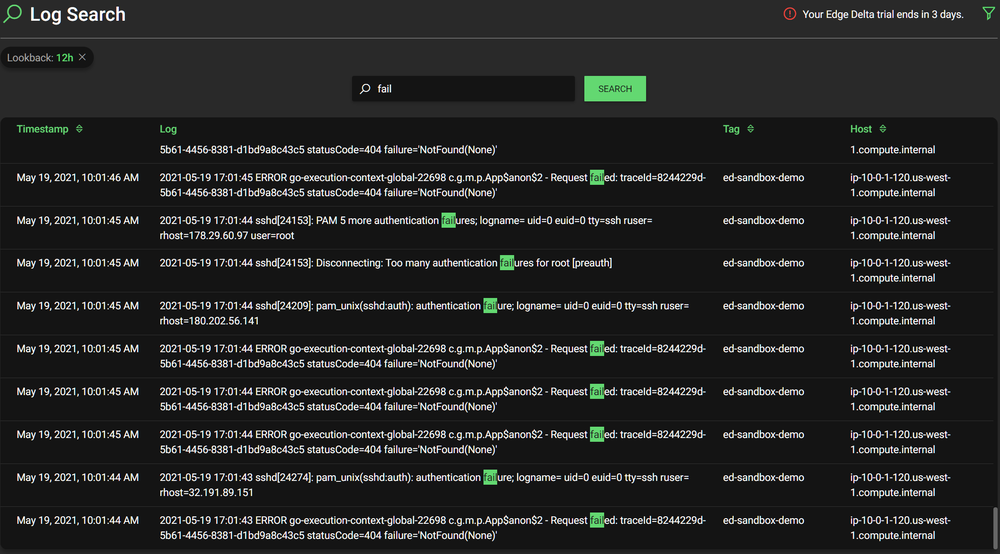
As mentioned earlier, after setting up the agent on a machine, you are automatically getting logs, metrics and other automatically generated insights out the gate. As an example—log search is immediately available, indexed behind the scenes on your behalf. In the image below, you can see a search for the string “fail”, which comes back immediately. No additional setup, tuning, index creation or schema design required.
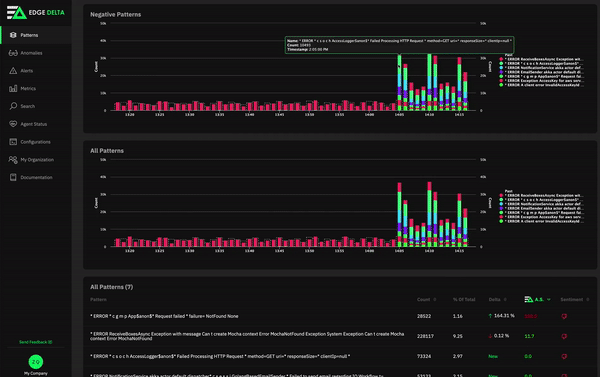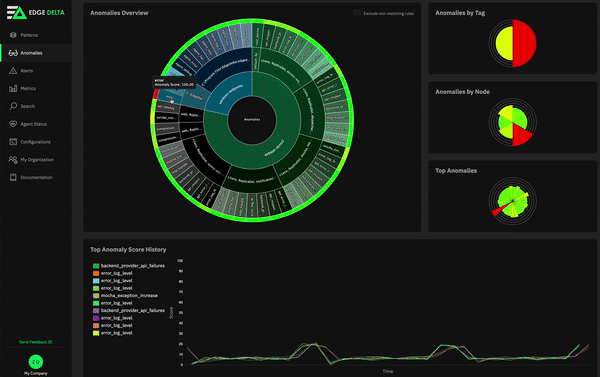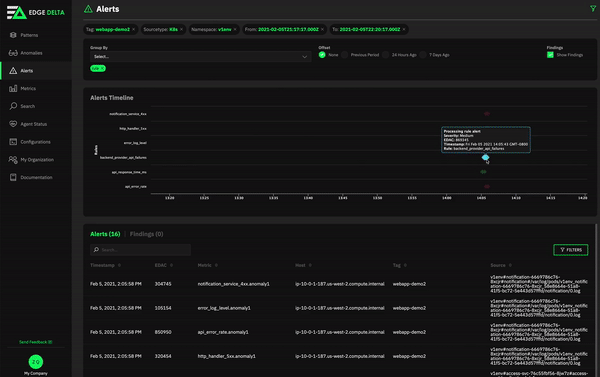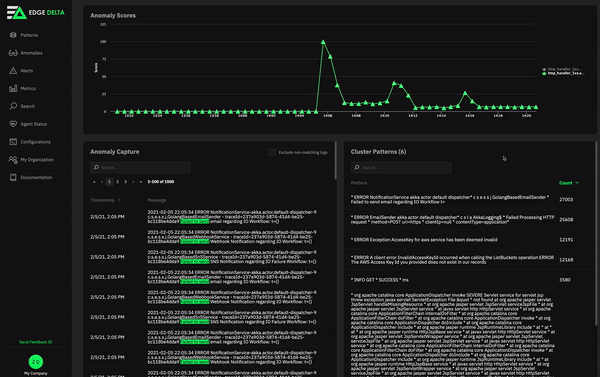
Agent Footprint and Performance
One of the biggest questions I hear from customers is about agents—too many, lack of desire to have them, etc. The problem is they are pretty much mandatory in order to move large datasets off a machine, but to preprocess at the edge, you have to be excellent in terms of minimal footprint and impact on CPU and RAM. We needed to set that this was the case with Edge Delta, so we did a bit of profiling on the hosts themselves. In the image below, this is running on an Ubuntu instance inside Hyper-V with 16GB RAM allocated.
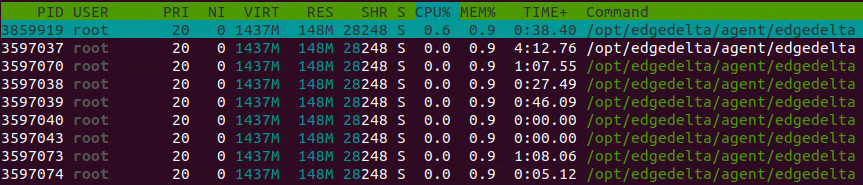
Here you can see CPU is mostly idle in the background, only showing up to use CPU when compressing data to upload. Memory footprint is less than 1% on this 16GB VM.
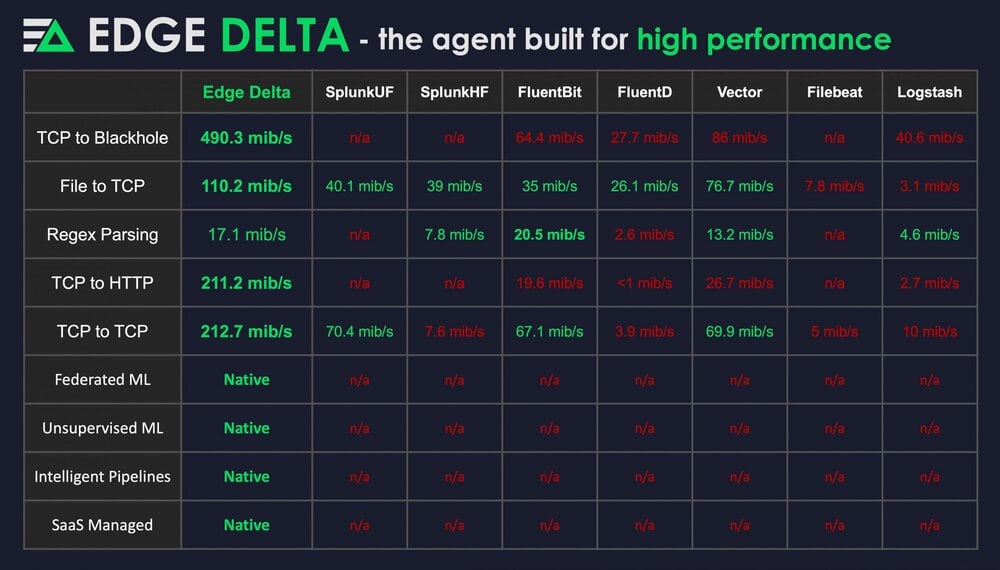
Agent speed comparison
One of the most scrutinized aspects of an agent is its performance. In high throughput scenarios, the last thing you want is your agent spooling to disk and then running a long de-spooling campaign while hosing your machine and thrashing disk with reads. The agent from Edge Delta was built with performance in mind, from the outset, with an order of magnitude (or more) performance against the competition:
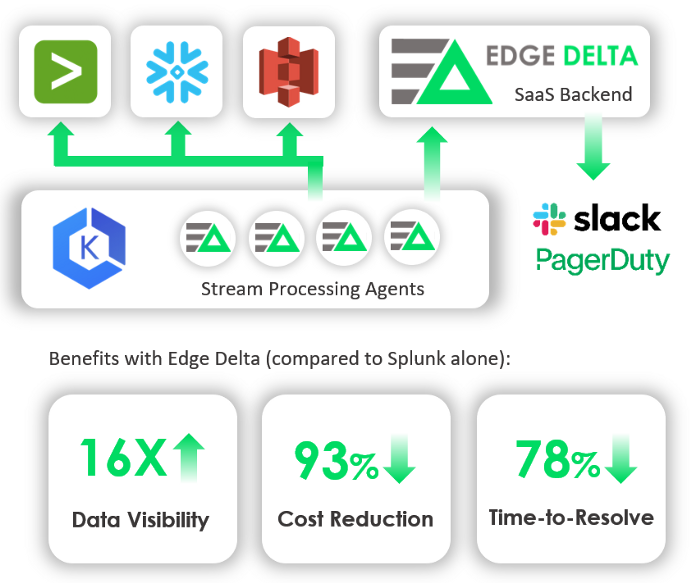
Fortune 100 Case Study
One Fortune 100 company was looking at solutions to gain a competitive advantage and put their service ahead of their industry, with the following requirements:
- Visibility to meet strict SLAs for uptime and availability and to reduce downtime.
- Privacy and Security for GDPR, CCPA, PCI standards for audit and compliance.
- Automated analytics including anomaly detection and predictive intelligence to reduce overhead/management costs.
- Low network/bandwidth reliance, to reduce strain of data transfer.
- Speed to reduce mean-time-to-detect as well as remediate production issues.

In their search for a technology, Edge Delta successfully provided:
- Federated learning to give full visibility into outlier and anomaly detection with no limitations in scope or visibility.
- Intelligence without raw data collection, helping to keep network utilization low and increase privacy and security at retail sites.
- Alerting orders of magnitude faster than existing centralized systems.
- Edge Delta was configured to enrich existing Sumo Logic instance and send alerts to Slack channels used by DevOps and Security Teams.

The end results from a data perspective were:

Conclusion
Menlo Ventures is excited to partner with the team at Edge Delta. The opportunity to invest in game changing core infrastructure for the new data stack is hard to pass up, especially when it has such an amazing team and founders like Ozan and Fatih. Check out a live demo at demo.edgedelta.com or, for more information, visit them at edgedelta.com, or email them at [email protected].

Tim is a partner at Menlo Ventures focused on early-stage investments that speak to his passion for AI/ML, the new data stack, and the next-generation cloud. His background as a technology builder, buyer, and seller informs his investments in companies like Neon (acquired by Databricks), Eve, Fleet, and Gimlet, among…




